

James Perkins
Whether it’s LLMs, GenAI, AI Agents, or Agentic AI, Artificial Intelligence (AI) is rapidly transforming the financial services landscape. From algorithmic trading and risk management to wealth advisory and compliance, AI workflows are becoming indispensable. Yet, the success of these systems hinges largely on one critical factor: data. This article explores how to optimise financial data for AI, offering techniques, and use cases across macroeconomic, pricing, reference, company, risk intelligence, and analytics data.
We invite you to watch the full companion video tutorial series which goes into more depth and provides additional details on the Financial Data & Analytics landscape and AI Data and Technology requirements:

Why Financial Data Matters in AI
It all starts with data. AI models are only as good as the data they consume. As David Schwimmer, CEO of LSEG put it at the 2025 World Economic Forum: ‘Without the right data, even the best algorithms can deliver mediocre—or worse, misinformed—results.’
In finance, data is complex, fragmented, and often governed by regulatory and licensing frameworks.
Financial data spans structured and unstructured formats, including real-time pricing, economic indicators, company filings, sentiment analysis and beyond. Optimising this data for AI requires domain expertise, robust infrastructure, and thoughtful governance.
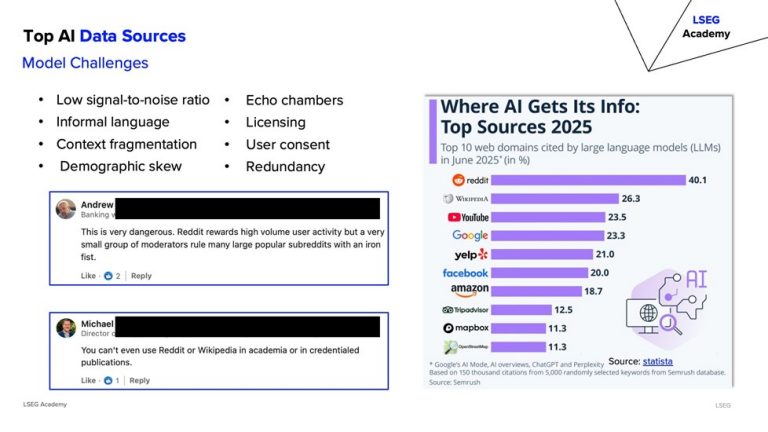
The Financial AI Landscape: Hype vs. Reality
While industry leaders are deploying GenAI assistants to automate research, draft emails, and support advisors, the reality across the financial industry is sobering. Up to 85% of AI projects in finance fail due to data quality issues, talent gaps, and misaligned strategies. Gartner predicts that 30% of GenAI projects will be abandoned after proof-of-concept due to poor data quality.

To succeed, financial institutions need to move beyond “success theater” and focus on foundational data optimisation.
This starts with understanding source data, including important nuances to datasets.
To support data & analytics practitioners to optimise financial data for AI, we present the major categories of financial data along with some related best practices, tips, and things to keep in mind when using each dataset in AI applications and workflows.
For a full list of financial datasets visit the LSEG Financial Data Catalogue.

Macroeconomic data includes indicators like CPI, GDP, unemployment rates, and central bank releases. These datasets are vital for forecasting models and signal enrichment in trading.

Optimisation Techniques:
- Use point-in-time (PIT) and real-time data to avoid “corrected past” bias.
- Apply feature engineering to handle sparsity and noise (e.g., rolling averages, lagged features).
- Separate final data from real-time signals to prevent causal misinterpretation.
Risks:
- Lagged and revised data can mislead models.
- Overestimation of prediction accuracy due to hindsight bias.
Use Cases:
- Macro forecasting
- Trading signal enrichment
- Economic sentiment analysis
Pricing data is foundational for valuing securities and includes real-time quotes, bid/ask spreads, volumes, and historical prices.
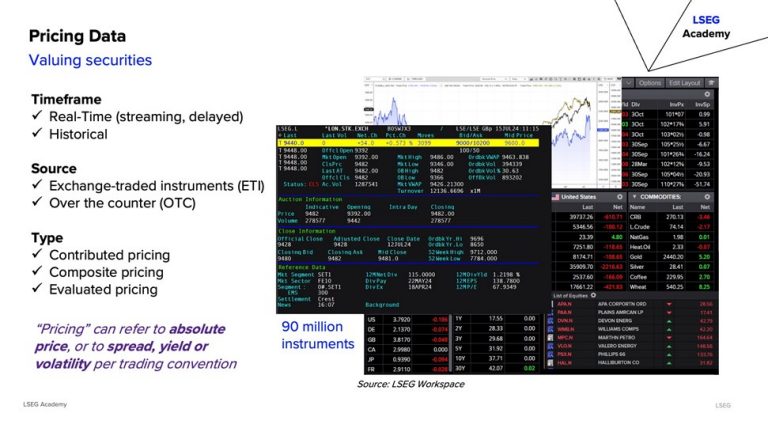
Optimisation Techniques:
- Filter trade qualifiers and detect outliers.
- Aggregate ticks using VWAP or price buckets.
- Manage securities lifecycle: delisting, expiration, corporate actions.
Risks:
- Noise amplification and anomalies.
- Look-ahead bias.
- Overfitting to historical prices.
Use Cases:
- High-frequency trading
- Real-time valuation models
- Market risk analysis
Reference data provides descriptive details about securities, entities, and instruments—such as maturity dates, coupon schedules, and ratings.
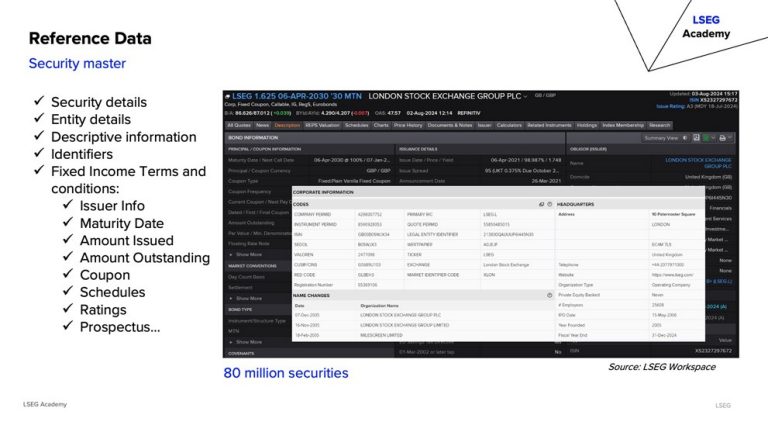
Optimisation Techniques:
- Create master mapping tables and use “golden sources.”
- Track data lineage and changes over time.
- Use peer group data to fill gaps.
Risks:
- Missing fields and inconsistent identifiers.
- Outdated data leading to model drift.
Use Cases:
- Trading and compliance systems
- Entity resolution
- Risk modeling
Symbology involves mapping and stitching datasets using identifiers like ISIN, CUSIP, SEDOL, and PermID.
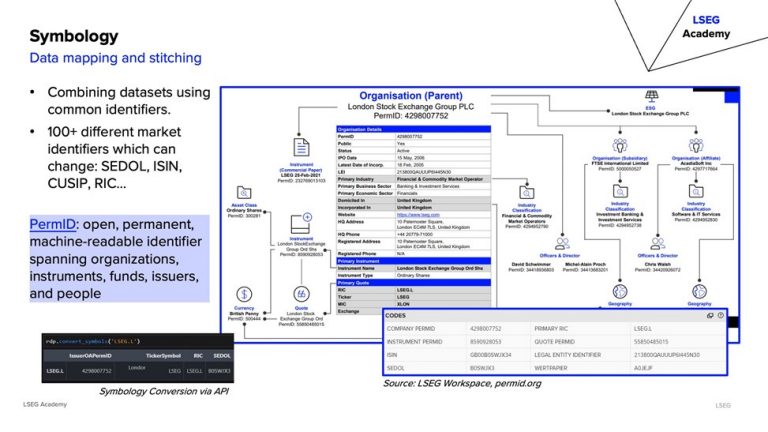
Optimisation Techniques:
- Implement a master symbology layer.
- Contextualise instruments beyond IDs.
- Use open standards like PermID for consistency.
Risks:
- Identifier changes due to corporate actions.
- Confusion from duplicate tickers across markets.
Use Cases:
- Cross-platform data integration
- Historical continuity in models
- Unified data pipelines
Unstructured data includes news, research reports, filings, and transcripts. It’s rich in insights but challenging to process.
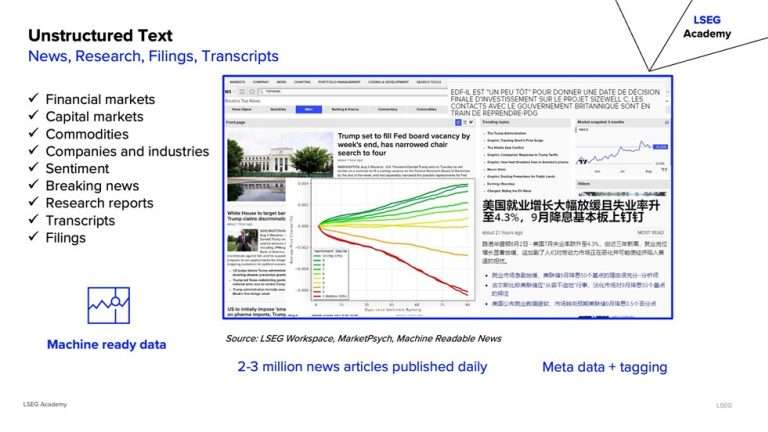
Optimisation Techniques:
- Use NLP for summarisation, classification, and sentiment analysis.
- Tag entities (dates, people, companies) and assign credibility scores.
- Align text data temporally with market events.
Risks:
- Misinformation and misinterpretation.
- Time lag between events and reactions.
Use Cases:
- Sentiment-driven trading
- Event detection
- Thematic portfolio construction
Company data encompasses structured financials and unstructured disclosures. It’s essential for valuation, benchmarking, and ESG analysis.
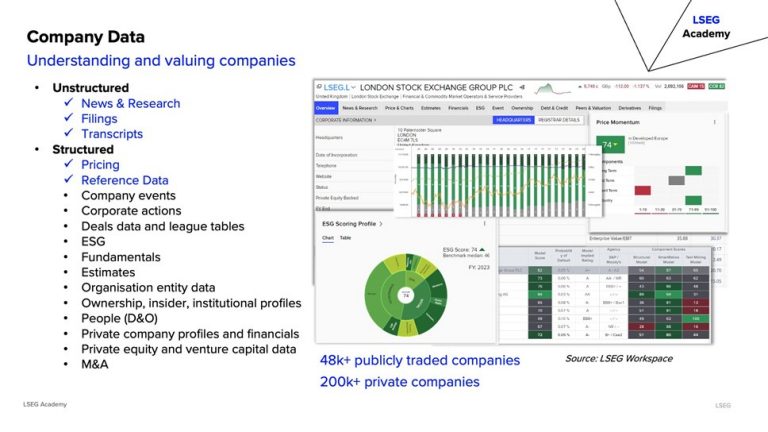
Optimisation Techniques:
- Standardise datasets and ensure auditability.
- Address gaps using peer metrics.
- Track revisions and reporting history.
Risks:
- Inconsistent definitions and delayed reporting.
- Missing values in private company data.
Use Cases:
- Equity research
- ESG scoring
- M&A analysis
Risk intelligence includes sanctions, PEPs, adverse media, and KYC data. It’s critical for compliance and fraud detection.
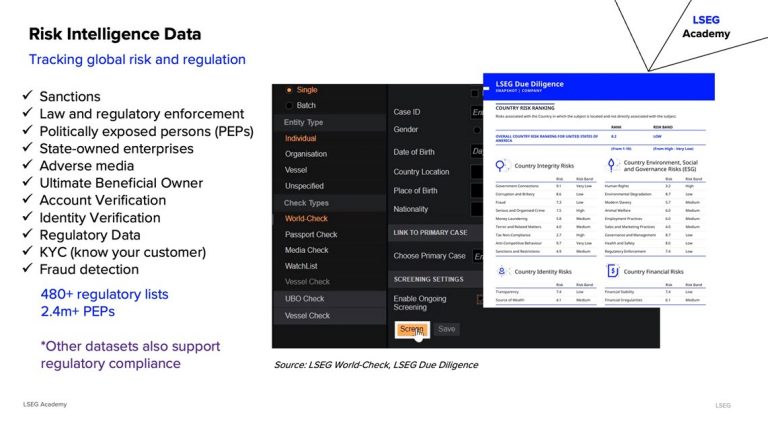
Optimisation Techniques:
- Format names, addresses, and dates consistently.
- De-duplicate and resolve entities.
- Flag consent for AI-based assessments.
Risks:
- Mishandling of personally identifiable information (PII).
- Regulatory changes and ethical concerns.
Use Cases:
- AML and KYC automation
- Fraud detection
- Political and legal risk analysis
Analytics are derived data used for valuations, hedging, spreads, and risk metrics. These could include local or cloud-based calculation engines and/or values calculated and delivered over datafeeds.
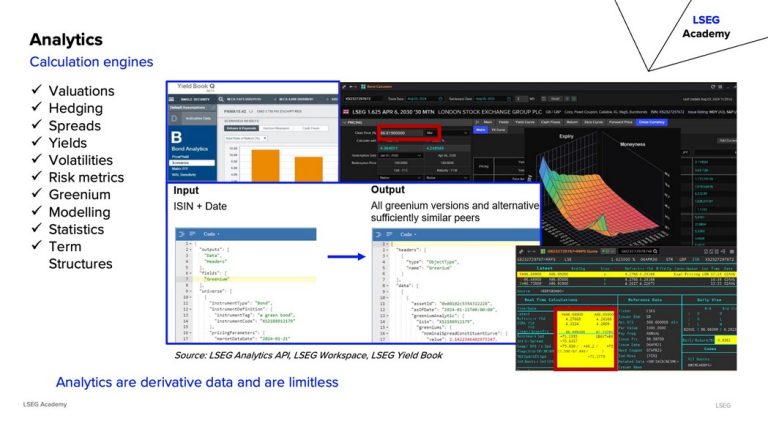
Optimisation Techniques:
- Implement explainability layers.
- Understand input data and model assumptions.
- Use hybrid models and strong governance.
Risks:
- Black-box models
- Regulatory non-compliance
- Model drift
Use Cases:
- Bond pricing
- Volatility modelling
- Portfolio risk management
How ready is your data for AI success?
As financial institutions continue to explore the transformative potential of AI, the path to success lies not in the sophistication of algorithms alone, but in the integrity, structure, and readiness of the data that fuels them. Optimising financial data is not a one-time task—it’s a continuous discipline that demands collaboration between data engineers, domain experts, and AI practitioners. The question is not whether your organisation will use AI, but how ready your data is to support it.